Reelle datasett#
Vi har lært å dele opp og analysere datafiler, men det finnes verktøy som gjør denne jobben enda enklere.
Med pandas er det å åpne og analysere datafiler en lek, men før vi ser på datafilene, må vi bli kjent med DataFrame-objekter.
Dataframes#
Den viktigste datatypen fra pandas er DataFrame.
En dataframe er en ordbok hvor nøklene er navn for kolonner, og verdiene er data i hver kolonne.
import pandas as pd
data = {
'Navn': ['Aelar', 'Thalia', 'Gorath', 'Elara', 'Borin', "Gronk"],
'Class': ['Ranger', 'Wizard', 'Barbarian', 'Rogue', 'Cleric', "Rogue"],
'Alder': [120, 35, 28, 25, 150, 34],
'Rase': ['Elf', 'Human', 'Half-Orc', 'Halfling', 'Dwarf', "Human"],
'Level': [5, 7, 6, 4, 8, 6]
}
df = pd.DataFrame(data)
print(df)
Navn Class Alder Rase Level
0 Aelar Ranger 120 Elf 5
1 Thalia Wizard 35 Human 7
2 Gorath Barbarian 28 Half-Orc 6
3 Elara Rogue 25 Halfling 4
4 Borin Cleric 150 Dwarf 8
5 Gronk Rogue 34 Human 6
Kolonner#
Man kan hente all data fra en kolonne ved å bruke kolonnens navn.
print(df["Navn"])
print()
print(list(df["Navn"]))
0 Aelar
1 Thalia
2 Gorath
3 Elara
4 Borin
5 Gronk
Name: Navn, dtype: object
['Aelar', 'Thalia', 'Gorath', 'Elara', 'Borin', 'Gronk']
Rader#
Man kan hente en spesifikk rad ved å bruke iloc().
print(df.iloc[4])
Navn Borin
Class Cleric
Alder 150
Rase Dwarf
Level 8
Name: 4, dtype: object
Filtrering#
Man kan filtrere resultater med en spesiell type indeksering.
print(df[df["Level"] >= 6]) # Henter ut alle som har level større enn eller likt 6
print()
print(df[df["Class"] == "Rogue"]) # Henter ut alle som er Rogue
Navn Class Alder Rase Level
1 Thalia Wizard 35 Human 7
2 Gorath Barbarian 28 Half-Orc 6
4 Borin Cleric 150 Dwarf 8
5 Gronk Rogue 34 Human 6
Navn Class Alder Rase Level
3 Elara Rogue 25 Halfling 4
5 Gronk Rogue 34 Human 6
Man kan også sette sammen flere filter ved å bruke tupler.
print(df[(df["Alder"] > 30) & (df["Alder"] <= 130)])
Navn Class Alder Rase Level
0 Aelar Ranger 120 Elf 5
1 Thalia Wizard 35 Human 7
5 Gronk Rogue 34 Human 6
Gjennomsnitt og sum#
Gjennomsnitt og sum finner man også lett.
print(f"Gjennomsnittlig alder: {df['Alder'].mean()} år")
print(f"Sum av hvert level: {df['Level'].sum()}")
Gjennomsnittlig alder: 65.33333333333333 år
Sum av hvert level: 36
Sortering#
Man kan sortere en DataFrame etter verdier.
print(df.sort_values(by="Alder", ascending=False))
Navn Class Alder Rase Level
4 Borin Cleric 150 Dwarf 8
0 Aelar Ranger 120 Elf 5
1 Thalia Wizard 35 Human 7
5 Gronk Rogue 34 Human 6
2 Gorath Barbarian 28 Half-Orc 6
3 Elara Rogue 25 Halfling 4
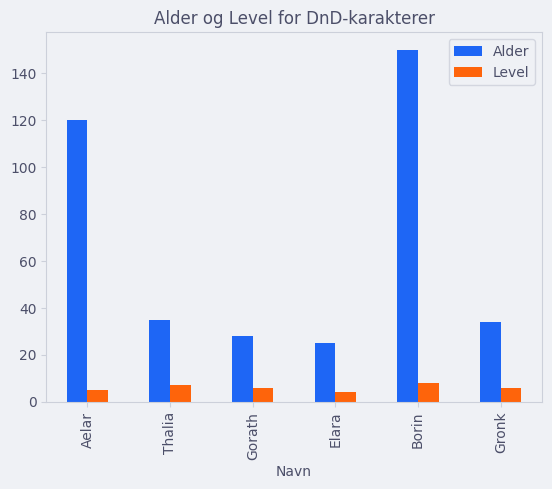
Søylediagram#
Det er innebygd matplotlib-funksjonalitet i pandas. La oss plotte et søylediagram/stolpediagram (bar-chart).
import pandas as pd
import matplotlib.pyplot as plt
df.plot(x="Navn", y=["Alder", "Level"], kind="bar", title="Alder og Level for DnD-karakterer")
plt.show()
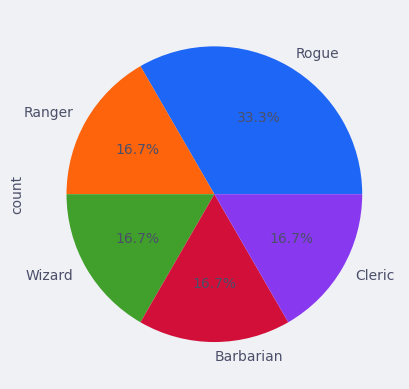
Sektordiagram#
Vi kan også lage et sektordiagram (pie-chart). Her teller vi opp hvor mange som er i hver "Class" og så plotter det som et sektordiagram.
df["Class"].value_counts().plot(kind="pie", autopct="%1.1f%%")
plt.show()
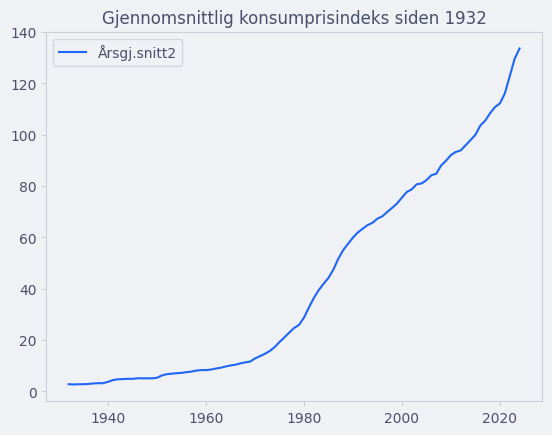
Linjediagram#
Vi kan plotte data over tid som et linjediagram. La oss se på en datafil fra SSB som viser konsumprisindeksen fra \(1932\) og frem til nå.
Du kan laste ned datafilen her.
;Årsgj.snitt2;Jan;Feb;Mar;Apr;Mai;Jun;Jul;Aug;Sep;Okt;Nov;Des
2024;133,6;132,0;132,3;132,6;133,7;133,5;133,8;134,5;133,3;133,7;134,5;134,9;134,8
2023;129,6;126,1;126,6;127,6;129,0;129,6;130,4;130,9;129,9;129,8;131,1;131,8;131,9
2022;122,8;117,8;119,1;119,8;121,2;121,5;122,6;124,2;123,9;125,6;126,0;125,8;125,9
2021;116,1;114,1;114,9;114,6;115,0;114,9;115,3;116,3;116,3;117,5;117,2;118,1;118,9
Vi ser at separatoren er semikolon ";" og at det brukes komma "," som desimaltegn. Datafilen har ikke et navn for første kolonne, fordi den er ment for å være indeksen til hvert sett med data. For å spesifisere dette kan vi bruke index_col-argumentet til read_csv().
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("konsumprisindeks.csv", sep=";", decimal=",", index_col = 0)
df.plot(kind="line", y=["Årsgj.snitt2"], title="Gjennomsnittlig konsumprisindeks siden 1932")
plt.show()
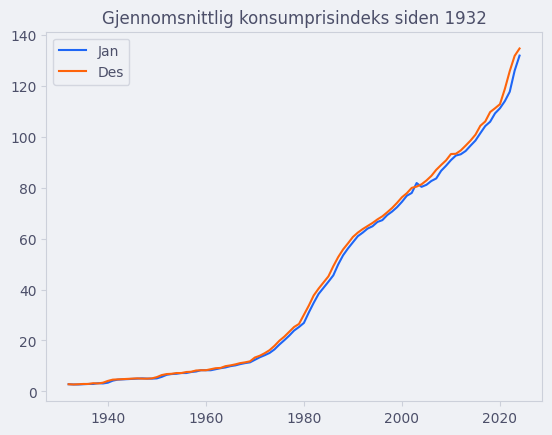
Vi kan også plotte flere plott i samme figur. La oss si at vi ønsker å sammenlikne KPI i januar med KPI i desember hvert år.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("konsumprisindeks.csv", sep=";", decimal=",", index_col = 0)
df.plot(kind="line", y=["Jan", "Des"], title="Gjennomsnittlig konsumprisindeks siden 1932")
plt.show()
Hoppe over linjer/rader#
Noen datafiler har ekstra linjer i starten av koden som ikke
Denne datafilen har masse kule data.
År,Kolonne1,Kolonne2,Kolonne3
2015,123,456,789
2016,987,654,321
For å hoppe over linjer kan vi bruke skiprows når vi laster inn data.
df = pd.read_csv("datafil.csv", skiprows=1)
Lagre filer#
Når man har en dataframe, kan man enkelt lagre den som en .csv eller .json-fil.
df.to_csv("adventurers.csv", index=False)
df.to_json("adventurers.json", index=False)
Telle opp#
Man kan telle opp hvor mange det er av hver kategori ved å bruke value_counts()-metoden
import pandas as pd
data = {
"ID" : ['ha81po', '4p2186', 'xpa1jx', '62gb2p', 'goh8ag', 'gxpbjj'],
"Parkert" : ["10:31", "09:34", "12:45", "09:45", "08:30", "08:46"],
"Type" : ["Bil", "ELBil", "Bil", "Bil", "ELBil", "Motorsykkel"],
"Dratt" : ["12:32", "16:32", "14:54", "12:34", "15:31", "15:47"],
"Besøk" : [32, 45, 34, 1, 50, 127],
"Tid" : ["02:01", "06:58", "02:09", "02:49", "07:01", "07:01"]
}
df = pd.DataFrame(data)
print(df["Type"].value_counts())
Type
Bil 3
ELBil 2
Motorsykkel 1
Name: count, dtype: int64
Største og minste verdier#
Man kan finne de n største eller minste verdiene med nsmallest- og nlargest.
print("=== Flest besøk ===")
print(df.nlargest(3, "Besøk")) # De tre bilene som har besøkt hyppigst.
print("=== Færrest besøk ===")
print(df.nsmallest(2, "Besøk")) # De to bilene som har besøkt minst
=== Flest besøk ===
ID Parkert Type Dratt Besøk Tid
5 gxpbjj 08:46 Motorsykkel 15:47 127 07:01
4 goh8ag 08:30 ELBil 15:31 50 07:01
1 4p2186 09:34 ELBil 16:32 45 06:58
=== Færrest besøk ===
ID Parkert Type Dratt Besøk Tid
3 62gb2p 09:45 Bil 12:34 1 02:49
0 ha81po 10:31 Bil 12:32 32 02:01
Man kan også bruke disse på kolonner for å bare få verdiene.
print(df["Besøk"].nlargest(3))
5 127
4 50
1 45
Name: Besøk, dtype: int64
Skrive ut bare noen kolonner#
Vi kan også skrive ut bare noen kolonner ved å indeksere i en DataFrame med en liste over kolonnenes navn.
print(df[["ID", "Besøk"]])
ID Besøk
0 ha81po 32
1 4p2186 45
2 xpa1jx 34
3 62gb2p 1
4 goh8ag 50
5 gxpbjj 127
Lage løkke gjennom DataFrame#
Vi kan lage løkker som går gjennom vår DataFrame for å regne ut nye ting. La oss si at prisen for parkeringen er \(0.2\) kr per minutt og at vi ønsker å legge til en ny kolonne df["Pris"].
For å lage en løkke gjennom en DataFrame kan vi bruke iterrows()-metoden. Denne gir oss en indeks og så en Series med all data i hver rad.
# Lager liste over verdier som skal legges til
pris_liste = []
# Får data fra iterrows
for indeks, rad in df.iterrows():
timer = int(rad["Tid"].split(":")[0])
minutter = int(rad["Tid"].split(":")[1])
pris = (timer * 60 + minutter) * 0.2
pris_liste.append(pris)
# Lager ny kolonne
df["Pris"] = pris_liste
print(df)
ID Parkert Type Dratt Besøk Tid Pris
0 ha81po 10:31 Bil 12:32 32 02:01 24.2
1 4p2186 09:34 ELBil 16:32 45 06:58 83.6
2 xpa1jx 12:45 Bil 14:54 34 02:09 25.8
3 62gb2p 09:45 Bil 12:34 1 02:49 33.8
4 goh8ag 08:30 ELBil 15:31 50 07:01 84.2
5 gxpbjj 08:46 Motorsykkel 15:47 127 07:01 84.2
Sette ny kolonne for indeks#
Noen ganger ønsker vi å endre hvilken kolonne som er indeksen for hvert objekt i vår DataFrame. Vi har sett på hvordan man kan bruke index_col når man laster inn data tidligere på denne siden.
Hvis man ønsker å endre hvilken kolonne som er indeks kan man bruke set_index()-metoden.
# Endrer DataFrame til å ha ID som sin indeks
df = df.set_index("ID")
print(df)
Parkert Type Dratt Besøk Tid Pris
ID
ha81po 10:31 Bil 12:32 32 02:01 24.2
4p2186 09:34 ELBil 16:32 45 06:58 83.6
xpa1jx 12:45 Bil 14:54 34 02:09 25.8
62gb2p 09:45 Bil 12:34 1 02:49 33.8
goh8ag 08:30 ELBil 15:31 50 07:01 84.2
gxpbjj 08:46 Motorsykkel 15:47 127 07:01 84.2
Lage ny kolonne#
I forrige eksempel laget vi en ny kolonne ved å kjøre en løkke gjennom data. For store datasett kan dette være ganske tregt. For enkle operasjoner som å legge sammen er det raskere å bruke innebygd Pandas.
import pandas as pd
data = {
"År" : [2001, 2002, 2003],
"Fødte" : [3004, 2345, 1301],
"Innflyttere" : [3423, 3638, 4523],
"Utflyttere" : [500, 525, 356]
}
df = pd.DataFrame(data)
df["Folkevekst"] = df["Fødte"] + df["Innflyttere"] - df["Utflyttere"]
print(df)
År Fødte Innflyttere Utflyttere Folkevekst
0 2001 3004 3423 500 5927
1 2002 2345 3638 525 5458
2 2003 1301 4523 356 5468
Manglende data#
Ikke alle datasett er perfekte. Datasett kan ha objekter med manglende data for noen kolonner. Dette må vi kunne håndtere. Kolonner hvor data er borte blir markert med None, NaN eller andre ting.
import pandas as pd
data = {
"ID" : ['ha81po', '4p2186', 'xpa1jx', '62gb2p', 'goh8ag', 'gxpbjj'],
"Parkert" : ["10:31", "09:34", "12:45", "09:45", "08:30", "08:46"],
"Dratt" : ["12:32", None, "14:54", "12:34", None, "15:47"],
}
df = pd.DataFrame(data)
print(df)
ID Parkert Dratt
0 ha81po 10:31 12:32
1 4p2186 09:34 None
2 xpa1jx 12:45 14:54
3 62gb2p 09:45 12:34
4 goh8ag 08:30 None
5 gxpbjj 08:46 15:47
Vi kan ignorere objekter som mangler data med dropna()-metoden.
print(df.dropna())
ID Parkert Dratt
0 ha81po 10:31 12:32
2 xpa1jx 12:45 14:54
3 62gb2p 09:45 12:34
5 gxpbjj 08:46 15:47
Vi kan også bruke dropna()-metoden på en kolonne (Series)
print(df["Dratt"].dropna())
0 12:32
2 14:54
3 12:34
5 15:47
Name: Dratt, dtype: object
Noen ganger ønsker vi å fylle de tomme plassene med noe. Vi kan bruke fillna()-metoden til det.
La oss si at dette er et parkeringssystem, og de som ikke har stemplet seg ut får en straff ved at de autimatisk får sin tid satt til 23:59 og må da betale mer!
print(df["Dratt"].fillna("23:59"))
0 12:32
1 23:59
2 14:54
3 12:34
4 23:59
5 15:47
Name: Dratt, dtype: object
Vi kan også endre selve DataFrame-objektet vårt for å kunne fortsette å analysere data videre med fikset data.
df["Dratt"] = df["Dratt"].fillna("23:59")
print(df)
ID Parkert Dratt
0 ha81po 10:31 12:32
1 4p2186 09:34 23:59
2 xpa1jx 12:45 14:54
3 62gb2p 09:45 12:34
4 goh8ag 08:30 23:59
5 gxpbjj 08:46 15:47
CSV-filer#
Filer med .csv er tekstfiler som følger en (litt slapp) standard.
Hver linje (rad) representerer et dataobjekt, for eksempel et spill, en bil eller en person.
Hver linje er delt opp i kolonner med et delimiter- eller separator-tegn, i dette tilfellet
,.
Plassering,Spillnavn,Konsoll
1,"Mario Kart DS",DS
2,"Hey You, Pikachu!",N64
3,"WarioWare, Inc.: Mega MicroGame$",GBA
4,"Horse Life 4: My Horse, My Friend, My Champion",3DS
Filer med .csv har ofte en første rad (eller flere rader) som forklarer hva hver kolonne representerer. Dette kalles en header. I tillegg brukes det noen ganger en annen delimiter enn ,, for eksempel ; eller \t, til tross for at det heter comma-separated values.
import pandas as pd
df = pd.read_csv("spill_enkel.csv")
print(df)
Plassering Spillnavn Konsoll
0 1 Mario Kart DS DS
1 2 Hey You, Pikachu! N64
2 3 WarioWare, Inc.: Mega MicroGame$ GBA
3 4 Horse Life 4: My Horse, My Friend, My Champion 3DS
Spesifisere separator og desimaltegn
Man kan spesifisere separator og desimaltegn som ekstra argumenter til read_csv().
Dette er nyttig hvis vi har en datafil som bruker andre tegn for separator og komma.
2023;129,6;126,1;126,6;127,6;129,0;129,6;130,4;130,9;129,9;129,8;131,1;131,8;131,9
2022;122,8;117,8;119,1;119,8;121,2;121,5;122,6;124,2;123,9;125,6;126,0;125,8;125,9
2021;116,1;114,1;114,9;114,6;115,0;114,9;115,3;116,3;116,3;117,5;117,2;118,1;118,9
df = pd.read_csv("datafil.csv", sep=";", decimal=",")
JSON-filer#
Filer med .json er tekstfiler som lagrer data på nesten samme måte som vi har gjort med ordbøker (lenke).
{
"1" : {
"Navn" : "Mario Kart DS",
"Konsoll" : "DS"
},
"2" : {
"Navn" : "Hey You, Pikachu!",
"Konsoll" : "N64"
},
"3" : {
"Navn" : "WarioWare, Inc.: Mega MicroGame$",
"Konsoll" : "GBA"
},
"4" : {
"Navn" : "Horse Life 4: My Horse, My Friend, My Champion",
"Konsoll" : "3DS"
}
}
import pandas as pd
df = pd.read_json("spill_enkel.json")
print(df)
print()
print(df[1]["Navn"]) # Henter navnet fra plassering 1
1 2 3 \
Navn Mario Kart DS Hey You, Pikachu! WarioWare, Inc.: Mega MicroGame$
Konsoll DS N64 GBA
4
Navn Horse Life 4: My Horse, My Friend, My Champion
Konsoll 3DS
Mario Kart DS
Får du problemer med æøå eller andre tegn?
Tekstfiler (.csv, .json, .txt) kan ha mange typer encoding.
df = pd.read_csv("datafil.csv", encoding="utf8")
Standard er utf8 men du finner fortsatt datafiler med andre encodings. Prøv disse også hvis du får problemer:
latin1ellerISO-8859-1windows-1252ISO-8859-15UTF-8-SIG
Dokumentasjonen
Dokumentasjonen for pandas finner du her (lenke).
Husk, å kunne lese dokumentasjon er en viktig ferdighet for en aspirerende programmerer! 🤓
Oppgaver#
Oppgave 1 🅰️
Lag din egen DataFrame. Første kolonne skal være Fag og andre kolonne skal være Karakter. Du kan finne på fag og karakterer.
Finn snittkarakteren.
Lag et søylediagram med labels som navnene på fagene og verdiene (høydene) som karakterene.
Bruk
pandastil å lagre dette som en datafilkarakterer.csv.
Oppgave 2 🎮
Jeg har rundet hundrevis av spill og kategorisert de i en .csv-fil.
Last ned filen her (lenke)
Skriv ut antallet spill i listen.
Skriv ut fordelingen mellom 1-ere, 2-ere, 3-ere, 4-ere og 5-ere.
Skriv ut hvor mange spill det er til de \(8\) mest populære spillkonsollene, i synkende rekkefølge.
(BONUS) Regn ut summen av de registrerte tidene i timer.
Oppgave 3 🏹
Handelsmannen Knoteknut Glimretå er en handelsmann som selger utstyr til eventyrere.
Last ned filen gnome_merchant_inventory.json.
Skriv ut en oversikt over de seks tingene han har mest av.
Løsningsforslag
import pandas as pd
df = pd.read_json("gnome_merchant_inventory.json")
print(df.nlargest(6, "antall"))
gjenstand antall
13 Fakkel 30
9 Piler (kogger) 25
19 Brød 25
7 Urter 20
2 Dolk 15
18 Vannflaske 15
Datafilen er generert av ChatGPT
Oppgave 4 ✨
Stjernestasjonen Epsilon-9 har et register over romskipene fra føderasjonen som har besøkt stasjonen.
Last ned filen starship_registry.csv.
Skriv ut en fin tabell over alle besøkene i kronologisk rekkefølge.
Løsningsforslag
import pandas as pd
df = pd.read_csv("starship_registry.csv", sep=";")
print(df.sort_values(by="Arrival Date"))
Registry Number Starship Name Class Arrival Date Captain Name Docking Bay
2 NX-01 Enterprise NX 2151-04-16 Jonathan Archer 8
24 NCC-1071 USS Shenzhou Walker 2256-01-11 Philippa Georgiou 23
23 NCC-21166 USS Discovery Crossfield 2256-02-11 Gabriel Lorca 22
11 NCC-638 USS Farragut Constitution 2257-11-21 Christopher Pike 9
0 NCC-1701 USS Enterprise Constitution 2265-02-14 James T. Kirk 5
22 NCC-1709 USS Hood Constitution 2267-03-19 Thomas Harris 21
19 NCC-1777 USS Lexington Constitution 2270-07-19 Burtell 19
17 NCC-1860 USS Intrepid Miranda 2270-08-19 Markel 17
21 NCC-2544 USS Potemkin Constitution 2275-05-12 Robert Wesley 20
1 NCC-1864 USS Reliant Miranda 2285-06-01 Clark Terrell 12
7 NCC-65530 USS Grissom Oberth 2286-02-23 Esteban 15
14 NCC-1701-A USS Enterprise Constitution Refit 2286-11-18 James T. Kirk 5
5 NCC-2000 USS Excelsior Excelsior 2290-01-01 Hikaru Sulu 10
13 NCC-2893 USS Stargazer Constellation 2333-05-22 Jean-Luc Picard 1
4 NCC-1701-D USS Enterprise Galaxy 2364-07-03 Jean-Luc Picard 7
18 NCC-3890 USS Hathaway Constellation 2365-02-14 William T. Riker 18
16 NCC-71807 USS Hood Excelsior 2365-04-05 Robert DeSoto 16
8 NCC-58928 USS Sutherland Nebula 2368-03-10 Shelby 14
9 NCC-71909 USS Defiant Defiant 2370-12-08 Benjamin Sisko 4
15 NX-74205 USS Defiant Defiant 2371-07-28 Benjamin Sisko 11
3 NCC-74656 USS Voyager Intrepid 2371-09-24 Kathryn Janeway 3
12 NCC-71099 USS Lakota Excelsior 2372-06-07 Erika Benteen 13
6 NCC-1701-E USS Enterprise Sovereign 2372-12-25 Jean-Luc Picard 6
10 NCC-80102 USS Prometheus Prometheus 2374-05-06 Doctor 2
20 NCC-74657 USS Voyager-B Intrepid 2379-09-24 Miral Paris 3
Datafilen er generert av ChatGPT
Oppgave 5 🎬
Norsk filmindustri har produsert noen sykt bra filmer gjennom tidene.
Last ned filen filmer.csv.
Lag en fin tabell. Brukeren skal kunne velge om man skal skrive ut i alfabetisk rekkefølge, eller etter utgivelse.
Skriv ut de tre mest sette filmene på kino.
Skriv ut de tre filmene med flest strømminger.
Løsningsforslag
import pandas as pd
df = pd.read_csv("filmer.csv")
def sjekk_svar():
svar = input("Velkommen til Norsk Filmindustri. Skriv ALFABETISK eller KRONOLOGISK: ")
if svar.upper() == "ALFABETISK":
print(df.sort_values(by="Navn"))
elif svar.upper() == "KRONOLOGISK":
print(df.sort_values(by="År"))
else:
print("Du skrev ikke riktig.")
sjekk_svar()
# Sjekker svar
print("=== Oversikt over filmer ===")
sjekk_svar()
# Skriver ut topp 3 kinofilmer.
print("\nOversikt over topp 3 filmer basert på kinobesøk.")
print(df.nlargest(3, "Kinobesøk"))
# Skriver ut topp 3 strømmefilmer
print("\nOversikt over topp 3 filmer basert på strømming.")
print(df.nlargest(3, "Strømminger"))
=== Oversikt over filmer ===
Velkommen til Norsk Filmindustri. Skriv ALFABETISK eller KRONOLOGISK: KRONOLOGISK
Navn År Kinobesøk Strømminger
14 Gutta boys 1999 95266 122787
0 OSLO 2000 9770 2665576
17 Kongen og krigen 2000 165423 452270
4 Torpedo: Lånekassen 2003 91845 774350
12 Forelsket: Ytre Enebakk 2005 123380 2645774
6 Jordskjelvet 2006 19524 827497
16 Forræderen 2006 107483 308763
10 Spinnville Sondre 2012 113911 2945296
5 Skogen 2013 87957 1570959
1 Krigen 2014 58819 2387531
8 Knerten blir kildesortert 2014 62394 873722
3 BLÜCHER 2015 187871 1809530
7 Enda en krigsfilm 2015 107948 1311115
11 Tante jobber for NAV 2015 40630 2751636
13 Sommer i Narvik 2015 90659 175462
19 Thor Heyerdahl 2016 169827 387362
18 Olsenbanden på førstegangstjeneste 2018 78856 1279729
2 Knerten: På farten 2019 125345 834912
15 Andre Verdenskrig 2022 137491 287087
9 WW2: Oslo 2024 163686 2788605
Oversikt over topp 3 filmer basert på kinobesøk.
Navn År Kinobesøk Strømminger
3 BLÜCHER 2015 187871 1809530
19 Thor Heyerdahl 2016 169827 387362
17 Kongen og krigen 2000 165423 452270
Oversikt over topp 3 filmer basert på strømming.
Navn År Kinobesøk Strømminger
10 Spinnville Sondre 2012 113911 2945296
9 WW2: Oslo 2024 163686 2788605
11 Tante jobber for NAV 2015 40630 2751636
Oppgave 6 ⚔️
Last ned datafilen raid.csv
Du skal lage et program som
Skriver ut de topp 3 mest populære
Class.Skriver ut hvor mange
PriestogPaladindet er til sammen.Lager et søylediagram eller sektordiagram som viser fordelingen av
Race.
For å gjennomføre et tokt må noen roller fylles. Vi trenger \(5\) Tank og \(10\) Healer. Resten får rollen DPS. Det er litt begrenset hva hver class kan gjøre.
Bare
WarriorellerDruidkan være tank.Bare
PaladinellerPriestkan være healer, menPriester dårligere somDPSog bør prioriteres som healer overPaladin.
Utvid programmet ditt til å skrive ut en oversikt over hele toktet med rollene
Tank,HealerogDPSfordelt riktig.
Løsningsforslag
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("raid.csv")
# De 3 mest populære classes
print("Mest populære classes:")
print(df["Class"].value_counts().nlargest(3))
# Summen av paladins og priests
print("Paladins + Priests:", len(df[df["Class"] == "Priest"]) + len(df[df["Class"] == "Paladin"]))
# Plotter Race
df["Race"].value_counts().plot(kind="pie", autopct="%1.1f%%")
plt.show()
# Lager liste over roller. Fyller med DPS først.
roller = ["DPS"] * len(df)
tanks, healers = 5, 10
# Legger til roller
for index, rad in df.iterrows():
if rad["Class"] == "Priest" and healers > 0:
roller[index] = "Healer"
healers -= 1
elif rad["Class"] == "Warrior" and tanks > 0:
roller[index] = "Tank"
tanks -= 1
elif rad["Class"] == "Druid" and tanks > 0:
roller[index] = "Tank"
tanks -= 1
# Legger til paladin healers hvis ikke priests har fylt opp.
if healers > 0:
for index, rad in df[df["Class"] == "Paladin"].iterrows():
if healers > 0:
roller[index] = "Healer"
healers -= 1
# Lager roller-kolonnen
df["Role"] = roller
# Skriver ut oversikt
print(df)
Mest populære classes:
Class
Warrior 8
Rogue 8
Paladin 7
Name: count, dtype: int64
Paladins + Priests: 11
Level Name Race Class Role
0 60 Melbert Dwarf Paladin Healer
1 60 PedroPedro Human Warlock DPS
2 60 KnutOve43 Gnome Mage DPS
3 60 exelcelsiorX Gnome Warrior Tank
4 60 Datamus Dwarf Hunter DPS
5 60 AlbionTerje Night Elf Rogue DPS
6 60 CarlaCute Gnome Rogue DPS
7 60 lordrolf Gnome Warrior Tank
8 60 Guthild Human Rogue DPS
9 60 perryx Dwarf Rogue DPS
10 60 benjamin_reichwald Night Elf Warrior Tank
11 60 commander_data Dwarf Rogue DPS
12 60 martin_mortensrud Dwarf Paladin Healer
13 60 johnperry Gnome Mage DPS
14 60 SugoiOtakuGamer Dwarf Paladin Healer
15 60 xonotic Human Rogue DPS
16 60 protonkanon34 Human Mage DPS
17 60 arnebjarne1985 Dwarf Warrior Tank
18 60 chiefkeefspleef Dwarf Hunter DPS
19 60 rotleif Night Elf Priest Healer
20 60 xleonhardeuler Night Elf Hunter DPS
21 60 MasterBlaster92 Dwarf Warrior Tank
22 60 SteinhardeStian Gnome Mage DPS
23 60 worf Gnome Warlock DPS
24 60 gleepglorpzoop Human Paladin Healer
25 60 3blue1brown Human Paladin Healer
26 60 agmund_aggro Gnome Warrior DPS
27 60 aimermaster99 Gnome Mage DPS
28 60 gamerGF Night Elf Hunter DPS
29 60 Amelia Dwarf Priest Healer
30 60 Trond Human Warrior DPS
31 60 politikerforakt Night Elf Druid DPS
32 60 CSMASTER Human Warrior DPS
33 60 jobber_med_excel Human Priest Healer
34 60 royhugo_tromsø Dwarf Hunter DPS
35 60 roblox13 Dwarf Priest Healer
36 60 suavementebesame Night Elf Rogue DPS
37 60 niels_bohr Human Rogue DPS
38 60 Barry56 Human Paladin Healer
39 60 InTheShadowOfTheHorns Human Paladin DPS
Oppgave 7 💸
Last ned filen lønnsutvikling.csv.
Tobias er lektor på VGS, men lurer på om han skal bytte jobb. Du har fått datafilen lønnsutvikling.csv som viser lønnsutviklingen siden \(2015\) i forskjellige relevante yrker for Tobias. Encoding for filen er latin1 (ISO 8859-1).
Du skal lage et program som
Lager et linjediagram som viser utviklingen i gjennomsnittslønnen for de forskjellige yrkene siden \(2015\).
Lager en tabell over hvert yrke som viser hvor mange prosent gjennomsnittslønnen har steget totalt f.o.m \(2015\) t.o.m \(2024\) og hvor mange prosent gjennomsnittslønnen har steget per år
Regner ut en projisert årslønn i \(2030\) ved å anta at stigningen fortsetter med den gjennomsnittlige prosentvise økningen per år som du regnet ut i forrige deloppgave.
Kilde for datafil: SSB Tabell 11418 Yrkesfordelt månedslønn, etter år, statistikkvariabel, yrke og statistikkmål (2025)
Løsningsforslag
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("lønnsutvikling.csv", encoding="latin1", sep=";")
# Linjediagram
df.plot(kind="line", x="år", title="Lønnsutvikling for ulike yrker siden 2015")
plt.show()
# Prosent økning siden 2015
print(f"{"YRKE":45} {"PROSENT ØKNING"} | {"P. PER ÅR"} | {"LØNN 2030"}")
for kol in df.columns:
if kol not in ["år", "statistikkvariabel"]:
gjennomsnitt = list(df[kol]) # Liste over gjennomsnitt
yrke = " ".join(kol.split()[1:-1]) + ":" # Litt finere navn på yrke
snitt_økning = (gjennomsnitt[-1] / gjennomsnitt[0])*100 # Siste delt på første lønn *100
økning_per_år = (snitt_økning - 100) / len(df) # Økning fordelt utover hvert år
vekstfaktor = 1 + (økning_per_år / 100) # Vekstfaktor for projisering fremover
lønn_2030 = 12 * gjennomsnitt[-1] * vekstfaktor ** 6 # 12 * månedslønn * vekstfaktoren 6 ganger for å få året 2030.
print(f"{yrke:45} {snitt_økning:^14.2f} | {økning_per_år:^9.2f} | {lønn_2030:^9.2f}")
YRKE PROSENT ØKNING | P. PER ÅR | LØNN 2030
Ledere av utdanning og undervisning: 138.56 | 3.86 | 1115200.62
Universitets- og høyskolelektorer/-lærere: 128.52 | 2.85 | 865417.58
Lektorer mv. (videregående skole): 133.77 | 3.38 | 880095.69
Programvareutviklere: 142.23 | 4.22 | 1171685.78