Reelle datasett#
Å skrive inn mange datapunkter er døllt og tar lang tid. Buuu! 👎 Tenk om vi kunne lese inn data fra store datafiler. Hadde ikke det vært nyttig?
La meg introdusere deg for pandas. Denne Python-pakken lar oss lese inn data fra datafiler helt automatisk! 🤯
Mange Python-installasjoner inkluderer denne pakken, men man kan også installere pakken ved å skrive pip install pandas i terminalvinduet.
Lese inn i Pandas#
La oss ta utgangspunkt i et datasett fra SSB om konsumprisindeksen fra og med 1930 til og med 2023.
Du kan laste ned datafilen her.
Hvis vi åpner filen konsumprisindeks.csv får vi en fil hvor de første linjene ser slik ut:
År;Årsgj.snitt2;Jan;Feb;Mar;Apr;Mai;Jun;Jul;Aug;Sep;Okt;Nov;Des
2023;129,6;126,1;126,6;127,6;129,0;129,6;130,4;130,9;129,9;129,8;131,1;131,8;131,9
2022;122,8;117,8;119,1;119,8;121,2;121,5;122,6;124,2;123,9;125,6;126,0;125,8;125,9
2021;116,1;114,1;114,9;114,6;115,0;114,9;115,3;116,3;116,3;117,5;117,2;118,1;118,9
2020;112,2;111,3;111,2;111,2;111,7;111,9;112,1;112,9;112,5;112,9;113,2;112,4;112,9
2019;110,8;109,3;110,2;110,4;110,8;110,5;110,6;111,4;110,6;111,1;111,3;111,6;111,3
2018;108,4;106,0;107,0;107,3;107,7;107,8;108,5;109,3;108,9;109,5;109,3;109,8;109,8
Hver linje (bortsett fra den første) inneholder informasjon om konsumprisindeksen hvert år. Den første verdien er året (f.eks 2023), så kommer årsgjennomsnittet (f.eks 129,6) og så kommer konsumprisindeksen hver måned etter det. Alle disse verdiene er adskilt med en semikolon ;.
Vi kan lese inn data fra en csv-fil i Pandas på denne måten:
import pandas as pd
df = pd.read_csv("konsumprisindeks.csv", delimiter=";", decimal=",") # Leser filen og spesifiserer at data skilles med semikolon ";" og desimaltall skrives med ","
print(df.head(3)) # Printer ut de tre første linjene.
År Årsgj.snitt2 Jan Feb Mar Apr Mai Jun Jul Aug \
0 2024 133.6 132.0 132.3 132.6 133.7 133.5 133.8 134.5 133.3
1 2023 129.6 126.1 126.6 127.6 129.0 129.6 130.4 130.9 129.9
2 2022 122.8 117.8 119.1 119.8 121.2 121.5 122.6 124.2 123.9
Sep Okt Nov Des
0 133.7 134.5 134.9 134.8
1 129.8 131.1 131.8 131.9
2 125.6 126.0 125.8 125.9
Plotte data fra Pandas#
Vi kan enkelt trekke ut de kolonnene vi ønsker og plotte de på denne måten.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("konsumprisindeks.csv", delimiter=";", decimal=",") # Leser filen og spesifiserer at data skilles med semikolon ";" og desimaltall skrives med ","
x = df["År"] # Henter ut x-verdier fra kolonnen "År"
y = df["Årsgj.snitt2"] # Henter ut y-verdier fra kolonnen "Årsgj.snitt2"
plt.plot(x, y) # Lager plot
plt.grid() # Viser rutenett
plt.show() # Viser plottet
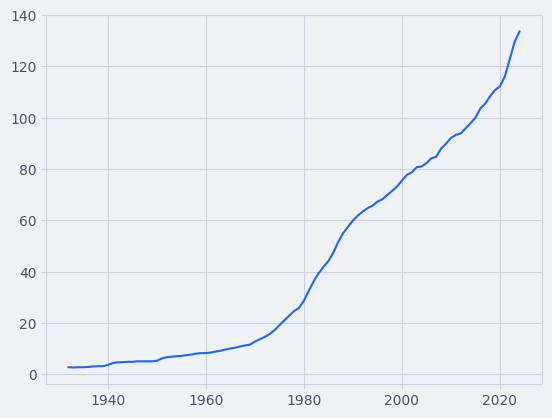
Wow! Nå har vi fått plottet konsumprisindeksen over mange år! Tenk hvor lang tid det hadde tatt hvis vi måtte skrive inn hvert punkt!
Kilde til data om konsumprisindeks: SSB.
Oppgaver#
Oppgave 1
I denne oppgaven skal vi plotte boligprisindeks for brukte boliger i Oslo/Bærum fra og med \(1992\) til og med \(2022\).
Last ned datafilen her.
Starten av datafilen står under. Legg merke til at desimaltallene er skrevet med punktum . her, ikke komma , som i eksempelet over. Legg også merke til at navnet på kolonnene må skrives helt likt som i filen.
"Region";"Boligtype";"År";"Prisindeks for brukte boliger"
"Oslo med Bærum";"Boliger i alt";"1992";13.6
"Oslo med Bærum";"Boliger i alt";"1993";14.1
"Oslo med Bærum";"Boliger i alt";"1994";16.9
"Oslo med Bærum";"Boliger i alt";"1995";17.8
Lag et plott over prisindeksen for brukte boliger over alle årene.